
人说在IT公司没有不忙的。你会发现每天RTX要闪烁几十个对话框是再正常不过的事情。可能你正好在写一个ppt,同时领导安排今天必须出一封邮件,刚在酝酿的时候突然还会有人电话催你开会,离开时刚好还有个朋友在QQ上请求帮忙找回密码,每天周而复始,逢人遍说忙似乎成了流行的口头禅。你会发现,时间永远也不够用,每天永远都有着“做不完”的事情。带着和所有人共同的问题,我了解了时间管理的方法论:GTD。下面我会带着一些自己的理解、更加直白的介绍一下GTD。
GTD就是Get Thing Done的缩写,翻译过来就是“把事情做完”,David Allen这本书的中文名叫:《尽管去做》。GTD的核心理念概括一句话,就是:你必须记录下来你要做的事,然后整理安排自己一一去执行了。说起来简单,做起来不容易,我们看一下GTD的五个核心原则是:收集、整理、组织、回顾、执行。

先记住这五个原则的先后顺序。
一、人类的大脑很强大,能存储很多东西,但让一个成年人回忆起所有童年的事情,很难。与其让大脑存放了这么多信息,不如把信息从脑海里拿出来记在纸上, 让大脑释放出来去思考如何做一件成功的事。所以,GTD的第一步是“收集”,把所有在脑海里浮现的信息(任务, 想法, 项目等等)记录到随身携带的小本子上(或者任何适合你的工具),把你的工作从大脑里面清出来,记录在可以看到的地方。GTD把这个叫做“收集箱”。

记录小提示:在纸上或其它设备里记录下工作时,应注意安排优先级,思考你的工作哪一项优先级最高,需要动脑筋。
记录的技巧:涉及到记录的工具和线上和线下两种情况。线上能提醒的可以使用Outlook的任务和日历。比如:几点要找张三打个打电话,几点要发给李四一封邮件,几点去开会。另外还可以使用Google Calendar Sync把Google日历和Outlook日历同步,随时在多个办公地点查看。
线下的工具是纸笔和手机,这里首先推荐的是纸和笔。当你“收集”完所有的信息后,就是“处理”了。
二、“处理(整理)”英文原意是Process,我提取了三点重要的内容:
1) 不把任何信息放回收集箱,处理完一件任务就打一个对勾。
2) 如果任何一项工作需要做,就马上执行去做(如果花的时间少于两分钟);或者委托别人完成,或者将其延期。
3) 否则就把它存档或删除、或是为它定义合适的目标与情境,以便下一步执行。

两分钟原则:不能不提一下处理的两分钟原则,我想更细的是:1秒+2分钟原则,对突然打断的事情,一秒钟评估,两分钟内能解决的,无论是任何事情,马上着手解决掉。如果不能在两分钟内解决,就进行下一步处理。这里不能拖,一件事一件事的来,一心不二用,两分钟处理完一件事,马上回到主要任务上来。
三、“组织”。“组织”应该是GTD中最关键的一点。“组织”主要分为对下一步行动的组织与对备份资料的组织。
下一步行动的组织一般可分为:等待处理清单、将来处理清单、下一步行动清单。
1) 等待处理清单主要是记录那些委派他人去做的工作,比如有封邮件问这件事有谁负责,可转交处理,如果你是主管,可安排下属去做。
2) 将来处理清单则是记录延迟处理且没有具体的完成日期的未来计划等等。
3) 下一步处理清单则是具体的下一步工作。而且如果一个任务涉及到多步骤的工作,那么需要将其细化成具体的项目。老外认为不能在两分钟钟内完成的、需要一系列动作来进行的任务叫作“项目”。
常使用Outlook做时间管理的,还可以把Outlook建@todo,@waiting,@next三个文件夹进行“组织”任务。记得在工作中看到托哥使用的是“每日待办”文件夹。
备份资料来自于对任务可行动的处理结果。对备份信息的组织主要就是一个文档管理系统,可用很多工具去存档这些资料,以前我使用的是网文快捕,现在发现Onenote也不错,推荐Onenote2007。
四、“回顾”。
我对回顾的理解是PDCA循环的一种方式,在每周回顾中,应该对比自己的年度目标,回顾自己在过去一周取得的进步,制定下一周的计划。如:回顾你的长期目标、中期目标和短期目标、回顾你在Onenote里的笔记、回顾你在Outook里的日程表、回顾你写在纸上的清单、回顾你的项目进展情况等等。
目前我采用的是每日回顾、每周回顾一次,对自己的工作和其它事情进行回顾,看看哪里做的不好,需要改进,重新做出调整计划。
五、“执行”就不用多讲,另外借用托哥的一个词“集中精神”,结合在一起就是:集中精神执行。
最后看一下GTD的工作流,作为对GTD几个核心原则的回顾。记住工作流,然后严格按这个工作流来处理你手头上的任务。
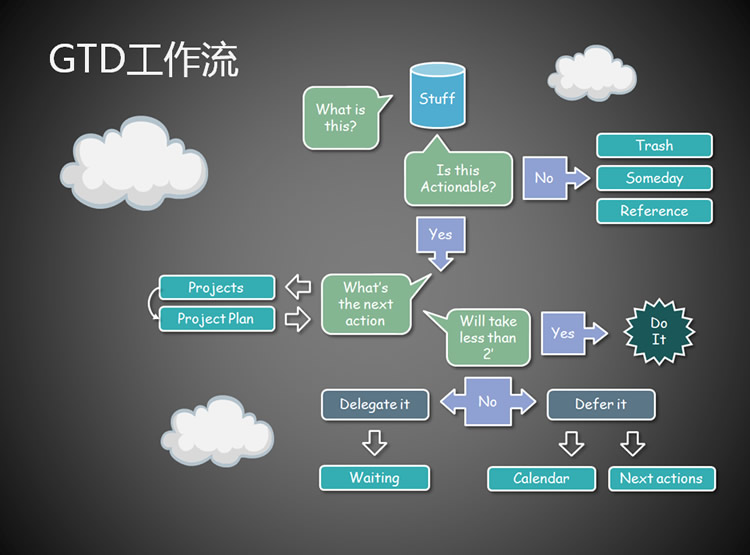
接近文章结尾,如果说时间GTD时间管理可以帮助我们做什么的化,我想无非是:更合理的安排时间、更宏观的看待工作、更方便归纳总结,更快速的提升工作效率,让你成为时间的主人。有人说采用GTD时间管理可以有更为明确的人生目标,我想,严格按着他来执行你的工作,不断的去完善,一定会有一个清晰的未来。下面是一些我经常浏览的GTD中文网站或论坛:
http://www.gtdlife.cn
http://groups.google.com/group/gtdlife?hl=zh-CN
http://www.mifengtd.cn/articles/category/gtd
http://www.gtdstudy.com/












